
Ever since things came back up after the Jan 5th outage, I’ve started to encounter regular timeouts. I will scroll past a couple dozen number posts and then it will stop as of there are no more. Within a few seconds, the application produces a time out error.
I use Boost for Lemmy as my client, but I’m not convinced that the issue is the app since switching my instance allows me to continue scrolling without a problem. And to be clear, prior to January 5th, I’ve never experienced a timeout in the app.
I’m curious if I’m the only one experiencing timeouts on Lemmy.ca. If so, then I’m curious if the admins are aware of any issue.
Is this gone now we’re on the new server?
With the server migration and the back end update, I really had high hopes. Haha. But alas… The All feed times out when I try to go to the next page with Boost. I went to the web UI and hit next it sure enough times out as well.
The secondary account I created doesn’t have the problem at all.
I appreciate you checking into the logs before. I’m still really curious about the cause, but it seems like I’m the only one struggling with this. I don’t really want to waste more of your time.
I will probably do a little more troubleshooting out of curiosity, but I don’t have high confidence that it’s going to be rectified.
No issues here. Using Jerboa.
I’ve experienced the occasional hiccup, but have no hard proof that it’s not my internet. There was one incident where my comment in this post got copied multiple times, but it was a single event so not enough to discern a pattern, and it could well have been a problem with my client instead of the server.
That is odd, I’m on Boost as well and haven’t noticed this. I’ll pass it along to the team and poke around!
The outage was a hardware issue and I don’t think we changed any site configuration since then. At least on our end, having the hardware replaced seemed to have fixed the occasional hiccups we were seeing.
In the meantime, could you try clearing the app’s cache? Boost lets you make a backup of the settings, which can help give peace of mind before doing resets.
If anyone else has this problem, please do share!
Thanks for the response. I have one inkling of an idea that might be a cause, but it really should affect the whole app rather than a single instance.
I’ve cleared the cache already but perhaps I might try backing up and clearing all data. Gonna keep monitoring for now.
Ugh. Decided to select the All feed and scroll away. And… it timed out after one “page”** worth of posts…
And boy did it stop on the worst post ever… (Note the time out error)
** I’m defining “page” as the number of posts displayed until you have to click the “next” on the standard web UI.
Still experiencing this on other apps as well. Attached is screenshot from Voyager. Still need to figure out a way to try and get some logs.
Any word on others experiencing this?
Can you please DM me your public IP address? Also if you can give me the specific timestamps (down to the second if you can) you got the error message so I can match up against logs.
So far I haven’t seen anything outside this thread, and I agree that it seems like an issue specific to certain instances.
I tried to summarize the details below and plan to look for more info. It could be related to something that changed in the Lemmy backend between versions 0.19.3 and 0.19.5, based on which instances are affected so far.
Some things you can test if you have a chance:
- See if the issue happens on a few other instances, up to you on which ones but it might help to try some with different backend versions. If it happens with every instance except lemmy.world and lemmy.sdf.org for example, then that might confirm it. This page has info on what version each instance is running: https://fedidb.org/software/lemmy
- Does it happen with the mobile web browser?
The summary
-
Details:
- Only happening to a few users, who are still able to access other instances just fine
- For lemmy.ca, it started around Jan 5th after a hardware related outage
- “I tried turning off my WiFi and just using data and it seemed to help, which is even weirder.”
- Clearing the app’s cache did not help
-
Instances Affected: lemmy.ca (BE: 0.19.7), sh.itjust.works (BE: 0.19.5)
-
Instances not affected: lemmy.world (UI: 0.19.3 BE: 0.19.3-7-g527ab90b7)
-
Clients: mobile apps (Boost, Sync, Voyager)
-
Issue:
- Regular timeouts, after scrolling past a ‘couple dozen’ posts it will not load any more, followed by a timeout error message (GlassHalfHopeful@lemmy.ca for lemmy.ca)
- Also unable to access comments (YungOnions@lemmy.world for sh.itjust.works)
-
Images:
- Boost:
- Voyager:
- Boost:
-
Other issue, but still could be related:
- Comment copied multiple times (lemmyng for lemmy.ca)
Alright, @otter@lemmy.ca. Here’s some more information.
General Findings
- Problem occurs on the WebUI as well while logged into Lemmy.ca.
- Problem occurs regardless of WebUI front-end used.
- Problem occurs regardless of Andriod apps used.
- Exception: Eternity (Nightly). I don’t know if they poll for information differently or what, but I can endlessly scroll without issue at the moment.
- Error outputs are unfortunately inconsistent between FEs. (The standard mobile UI shows no error and sim.)
- Problem occurs both with and without VPNs employed.
Findings by Server
- lemmy.ca: BE: 0.19.7
- Problem instance and My primary.
- lemmy.world: BE: 0.19.3-7-g527ab90b7
- No issues observed. Logged in with Boost & Voyager using alternate account.
- beehaw.org: BE: 0.18.4
- No issues observed. Logged in with Boost using alternate account.
- lemm.ee: BE: 0.19.8
- No issues observed. Logged in Anonymously via Voyager Android App.
- feddit.uk: BE: 0.19.7
- Will try if/when they approve the account request.
- Really want to try this since they are using the same BE as lemmy.ca
- lemmy.sdf.org and another instance with BE: 0.19.3
- Will try if/when they approve my alt accounts. If someone knows an app where I can browser sdf as anonymous, then I can do it now.
Errors By Application Note the differences in how the error is presented. Sending timestamps and IP to @Shadow@lemmy.ca via DM for the following:
- Boost (Android)
- Voyager (Android)
- Photon as Android Firefox PWA via lemmy.ca
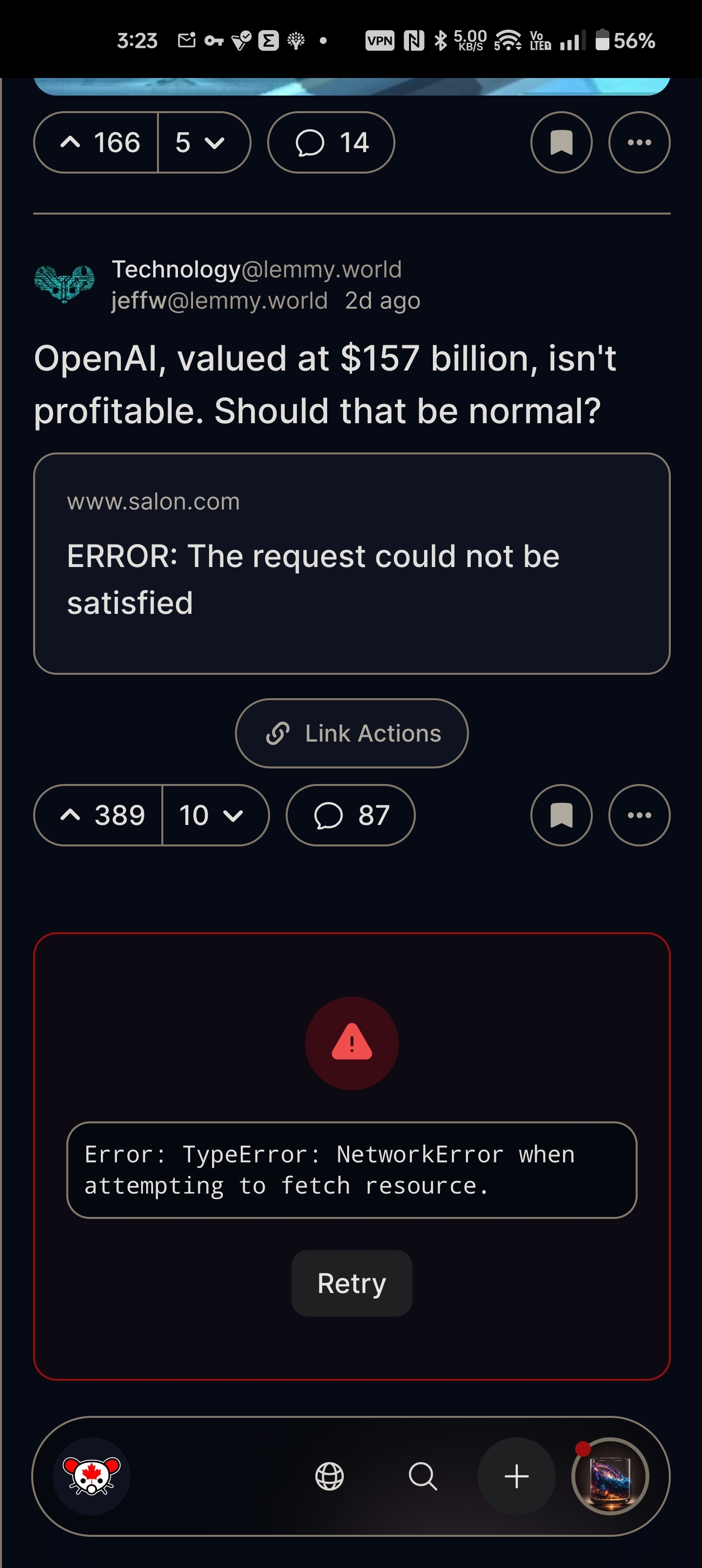
- Lemmy WebUI via lemmy.ca
simply renders empty after the timeout. this was page 2
I suspect something might be funky with your account, rather than the network / apps. The timeout message is a lie, you’re really getting 400 / 499 errors that seem to be related to this lemmy error message:
2025-01-20T17:30:03.366014Z WARN Error encountered while processing the incoming HTTP request: lemmy_server::root_span_builder: NotAModOrAdmin: NotAModOrAdmin 0: lemmy_api_common::utils::check_community_mod_of_any_or_admin_action at crates/api_common/src/utils.rs:102 1: lemmy_api::local_user::report_count::report_countand:
2025-01-20T20:39:43.202677Z WARN Error encountered while processing the incoming HTTP request: lemmy_server::root_span_builder: CouldntFindPerson: Record not found 0: lemmy_apub::fetcher::resolve_actor_identifier at crates/apub/src/fetcher/mod.rs:22 1: lemmy_apub::api::read_person::read_personI wonder if it could be a bug related to the unicode name you’ve got going on. Did you set that recently, or has it been like that since day 1?
I just restarted all of our docker containers, see if that helps? If not, try setting a normal name and confirm if that changes things?
Well, I’ve checked out the source. (Rust is very foreign to me. Haha.) However, I can see the offending code now. I don’t really have the means to dig further, but I did learn the following:
RE: First error
- the error comes from a method performing the following: “Check that a person is either a mod of any community, or an admin.”
- the code block where NotAModOrAdmin error is returned as had the error check was refactored and moved. but… it looks like it will still act the same in later versions of the BE.
- what i cannot say is WHY this being checked. i am neither, so it is_mod_of_any_or_admin == false. but… so what? i neither know why the check is occurring nor why it matters.
- the stack trace shows preceding calling method which is report_count(), but no idea what happens before that or why… so unfortunately i didn’t learn too much about this “error.” i wonder if it would happen still if I was the mod of any given community. it should pass, but again… what would that matter and why? i am literally only trying to load a list of posts from the front page. (seems to happen more often when looking at “All” posts)
Re: Second Error
- resolve_actor_identifier make two attempts to get the actor (my user account me thinks). the call to DbActor::read_from_name_and_domain() seems to fail and so webfinger_resolve_actor() is called which also does not come back OK.
- it’s possible my user isn’t being found due to network latency, issues with server response time, or who knows what else.
So the cause? Who knows. Ugh.
Even though this started for me after the defective power supply was replaced… if that’s ALL they changed (including not adjusting any server settings at all)… then we shouldn’t see this at all. I wonder still if something happened while writing to the DB and the power cut. perhaps something related to my account is unhappy in the DB. Who knows.
You all will be changing hardware providers in the near future. The next version of the BE, which you will eventually update, also adjusts the affected code a bit. And so… maybe it will resolve itself?
One can hope.
I’m having the same issues with sh.itjust.works. Also on Boost, also having the same Time Out issues. Can’t even access comments. I even tried posting to this thread using my sh.itjust.works profile and it just failed to work. If I switch to another profile like the one I’m using atm everything works OK. I also tried
SignalSync, same issues, so it doesn’t appear to be app related.Its really weird.
Perhaps I need to stick on a different instance for a little while to see if it happens again.
And I guess I should try out another client to see if I experience the same problems there.
I’m a little confused by your Signal comment though. Is there a Lemmy client with that name?
And I guess I should try out another client to see if I experience the same problems there
Are you on mobile? If so I tried turning off my WiFi and just using data and it seemed to help, which is even weirder.
I’m a little confused by your Signal comment though. Is there a Lemmy client with that name?
No, sorry, I meant Sync. Amended.
When I time out again, I will try mobile and see what happens. That would be strange for it to work then… But since the network is reset in the process and the data is taking a different route… That would at least mean something.
I just noticed you are posting from lemmy.world rather than sh.itjust.works. when you say you are having the same problem as me, are you signed on to the sh.itjust.works instance when you get the time out?
My primary instance is lemmy.ca and I am signed on to that instance when I have the timeouts.
Yes, I’m having the problems with sh.itjust.works instance. I’ve moved to Lemmy.world whilst this issue is ongoing just so I can actually use Lemmy.
Ha! Exactly. I made a .world for this reason.
I just saw your other post about this. Are you specifically getting “time out” like I am or other messages?
Yes, Time Out, same as you.




