I don’t use either. But as far as I know, neither service currently charges for generation of images. I don’t know if there’s some sort of different rate-limit that favors one over the other, or another reason to use Bing (perhaps Midjourney’s model is intentionally not trained on Sailor Moon?), but I do believe that Midjourney can do a few things that Bing doesn’t.
One of those is inpainting. Inpainting, for those who haven’t used it, lets one start with an existing image, create a mask that specifies that only part of the image should be regenerated, and then regenerate that part of the image using a specified prompt (which might differ from the prompt used to generate the image as a whole). I know that Thelsim’s used this feature before with Midjourney, because she once used it to update an image with some sort of poison witch image with hands over a green glowing pot, so I’m pretty sure that it’s available to Midjourney general users.
I know that you recently expressed frustration with Bing’s Image Creator’s current functionality, wanted more.
Inpainting’s time-consuming, but it can let a lot of images be rescued, rather than having to just re-reroll the whole image. Have you tried using Midjourney? Was there anything there that you found made it not acceptable?
The inpainting has improved a lot since then. Recently they introduced an external editor that allows you to do more accurate inpainting and even retexturing.
For example, taking one of the images here.
With retexturing I can write:
A1900s photograph, of sailor moon and politicians and a xenomorph, in congress
And have it transformed while keeping the original characters:
There’s also the option to repaint:
And to expand the image:
But things it doesn’t do well is accurate stuff, like flags, characters, that kind of thing. It likes to hallucinate a little so, for example, you won’t get a perfect flag. And even a sailor moon will often look a bit off-brand.
Thanks for trying it out! Both the inpainting and outpainting – the expansion – worked better than I’d expected, though I dunno if that’s exactly what M0oP0o’s after.
The inpainting has definitely improved, a while ago it was impossible to get it to properly match the style of the rest of the image. You could always see where the original was altered. Now it blends much better with the rest of the image.
And inpainting of non-generated images is a recent thing, before that you could only alter images that Midjourney originally created.
Another one I completely forgot about, I also have access to the NovelAI image generator, which is completely anime trained. It has a ton of different features that I never use. I just use it as a writing aid for myself, the image generation was kind of tacked on later but grew into it’s own thing.
There’s a mood changer:
Line art (which removes the dollar bill, weirdly enough ) :
I will give it a try as well always good to have more options, and I am not 100% only free options.
Funny note on the images. Mine where failures because I could not get a normal sailormoon with a floating bill with wings and a halo. Its funny to see all these with the anglemoon and normal money.
I have tried midjourney before. The results where… Underwhelming. Lots of odd artifacting, slow creation time and yes it had some issues with sailormoon.
I might try again, as it has been a while. It would be nice to have more control.
Oh I also tried local generation (forgot the name) and wooooow is my local PC bad at pictures (clearly can’t be my lack of ability it setting it up).
Lots of odd artifacting, slow creation time and yes it had some issues with sailormoon.
It probably isn’t worth the effort for most things, but one option might also be – and I’m not saying that this will work well, but a thought – using both. That is, if Bing Image Creator can generate images with content that you want but gets some details wrong and can’t do inpainting, but Midjourney can do inpainting, it might be possible to take a Bing-generated image that’s 90% of what you want and then inpaint the particular detail at issue using Midjourney. The inpainting will use the surrounding image as an input, so it should tend to try to generate similar image.
I’d guess that the problem is that an image generated with one model probably isn’t going to be terribly stable in another model – like, it probably won’t converge on exactly the same thing – but it might be that surrounding content is enough to hint it to do the right thing, if there’s enough of that context.
I mean, that’s basically – for a limited case – how AI upscaling works. It gets an image that the model didn’t generate, and then it tries to generate a new image, albeit with only slight “pressure” to modify rather than retain the existing image.
It might produce total garbage, too, but might be worth an experiment.
What I’d probably try to do if I were doing this locally is to feed my starting image into the thing to generate prompt terms that my local model can use to generate a similar-looking image, and include those when doing inpainting, since those prompt terms will be adapted to trying to create a reasonably-similar image using the different model. On Automatic1111, there’s an extension called Clip Interrogator that can do this (“image to text”).
Searching online, it looks like Midjourney has similar functionality, the /describe command.
It’s not magic – I mean, end of the day, the model can only do what it’s been trained on – but I’ve found that to be helpful locally, since I’d bet that Bing and Midjourney expect different prompt terms for a given image.
Oh I also tried local generation (forgot the name) and wooooow is my local PC bad at pictures (clearly can’t be my lack of ability it setting it up).
Hmm. Well, that I’ve done. Like, was the problem that it was slow? I can believe it, but just as a sanity check, if you run on a CPU, pretty much everything is mind-bogglingly slow. Do you know if you were running it on a GPU, and if so, how much VRAM it has? And what you were using (like, Stable Diffusion 1.5, Stable Diffusion XL, Flux, etc?)
If that’s 16GB, that should be more than fine for SDXL.
So, I haven’t done much with the base Stable Diffusion XL model. I could totally believe that it has very little Sailor Moon training data. But I am confident that there are models out there that do know about Sailor Moon. In fact, I’ll bet that there are LoRAs – like, little “add-on” models that add “knowledge” to a checkpoint model on Civitai specifically for generating Sailor Moon images.
Looks like I don’t have vanilla SDXL even installed at the moment to test.
downloads vanilla
Here’s what I get from vanilla SDXL for “Sailor Moon, anime”. Yeah, doesn’t look great, probably isn’t trained on Sailor Moon:
Time taken: 8 min. 18.0 sec. (to do a batch of 20, and with 30 steps, whereas I typically use 20…used 30 because the LoRA example image did, don’t wanna go experiment a bunch).
I grabbed some of those prompt terms from the example images for the Sailor Moon LoRA on Civitai. Haven’t really tried experimenting with what works well. I dunno what’s up with those skirt colors, but it looks like the “multicolored skirt, white skirt” does it – maybe there are various uniforms that Sailor Moon wears in different series or something, since it looks like this LoRA knows about them and can use specific ones, as they have those different skirts and different prompt terms on the example images.
I just dropped the Animagine model in the models/Stable-diffusion directory in Automatic1111, and the Sailor Moon Tsukino Usagi LoRA in the models/Lora directory, chose the checkpoint model, included that <lora:sailor_moon_animaginexl_v1:0.9> prompt term to make the render use that LoRA and some trigger terms.
That’s 1024x1024. Then doing a 4x upscale to a 16GB 4096x4096 PNG using SwinIR_4x in img2img using the SD Ultimate Upscale script (which does a tiled upscale, so memory shouldn’t be an issue):
The above should be doable with an Automatic1111 install and your hardware and the above models.
EDIT: On Civitai, when you view example images, you can click the little “i” in a circle on the image to view what settings they used to create them.
EDIT2: It looks like the same guy that made a LoRA for Sailor Moon also did LoRAs for the other characters in her series, so if you want, like, training on Sailor Mars or whatever, looks like you could grab that and also add knowledge about her in.


{kind=link}














@M0oP0o@mander.xyz, as far as I can tell, you always use Bing Image Creator.
And as far as I can tell, @Thelsim@sh.itjust.works always uses Midjourney.
I don’t use either. But as far as I know, neither service currently charges for generation of images. I don’t know if there’s some sort of different rate-limit that favors one over the other, or another reason to use Bing (perhaps Midjourney’s model is intentionally not trained on Sailor Moon?), but I do believe that Midjourney can do a few things that Bing doesn’t.
One of those is inpainting. Inpainting, for those who haven’t used it, lets one start with an existing image, create a mask that specifies that only part of the image should be regenerated, and then regenerate that part of the image using a specified prompt (which might differ from the prompt used to generate the image as a whole). I know that Thelsim’s used this feature before with Midjourney, because she once used it to update an image with some sort of poison witch image with hands over a green glowing pot, so I’m pretty sure that it’s available to Midjourney general users.
I know that you recently expressed frustration with Bing’s Image Creator’s current functionality, wanted more.
Inpainting’s time-consuming, but it can let a lot of images be rescued, rather than having to just re-reroll the whole image. Have you tried using Midjourney? Was there anything there that you found made it not acceptable?
The inpainting has improved a lot since then. Recently they introduced an external editor that allows you to do more accurate inpainting and even retexturing.
For example, taking one of the images here.
With retexturing I can write:

A 1900s photograph, of sailor moon and politicians and a xenomorph, in congressAnd have it transformed while keeping the original characters:
There’s also the option to repaint:

And to expand the image:
But things it doesn’t do well is accurate stuff, like flags, characters, that kind of thing. It likes to hallucinate a little so, for example, you won’t get a perfect flag. And even a sailor moon will often look a bit off-brand.
Thanks for trying it out! Both the inpainting and outpainting – the expansion – worked better than I’d expected, though I dunno if that’s exactly what M0oP0o’s after.
I don’t know, but I felt like sharing :)
The inpainting has definitely improved, a while ago it was impossible to get it to properly match the style of the rest of the image. You could always see where the original was altered. Now it blends much better with the rest of the image.
And inpainting of non-generated images is a recent thing, before that you could only alter images that Midjourney originally created.
Yeap, that is functionality I could use. Will have to try later.
Another one I completely forgot about, I also have access to the NovelAI image generator, which is completely anime trained. It has a ton of different features that I never use. I just use it as a writing aid for myself, the image generation was kind of tacked on later but grew into it’s own thing.
There’s a mood changer:
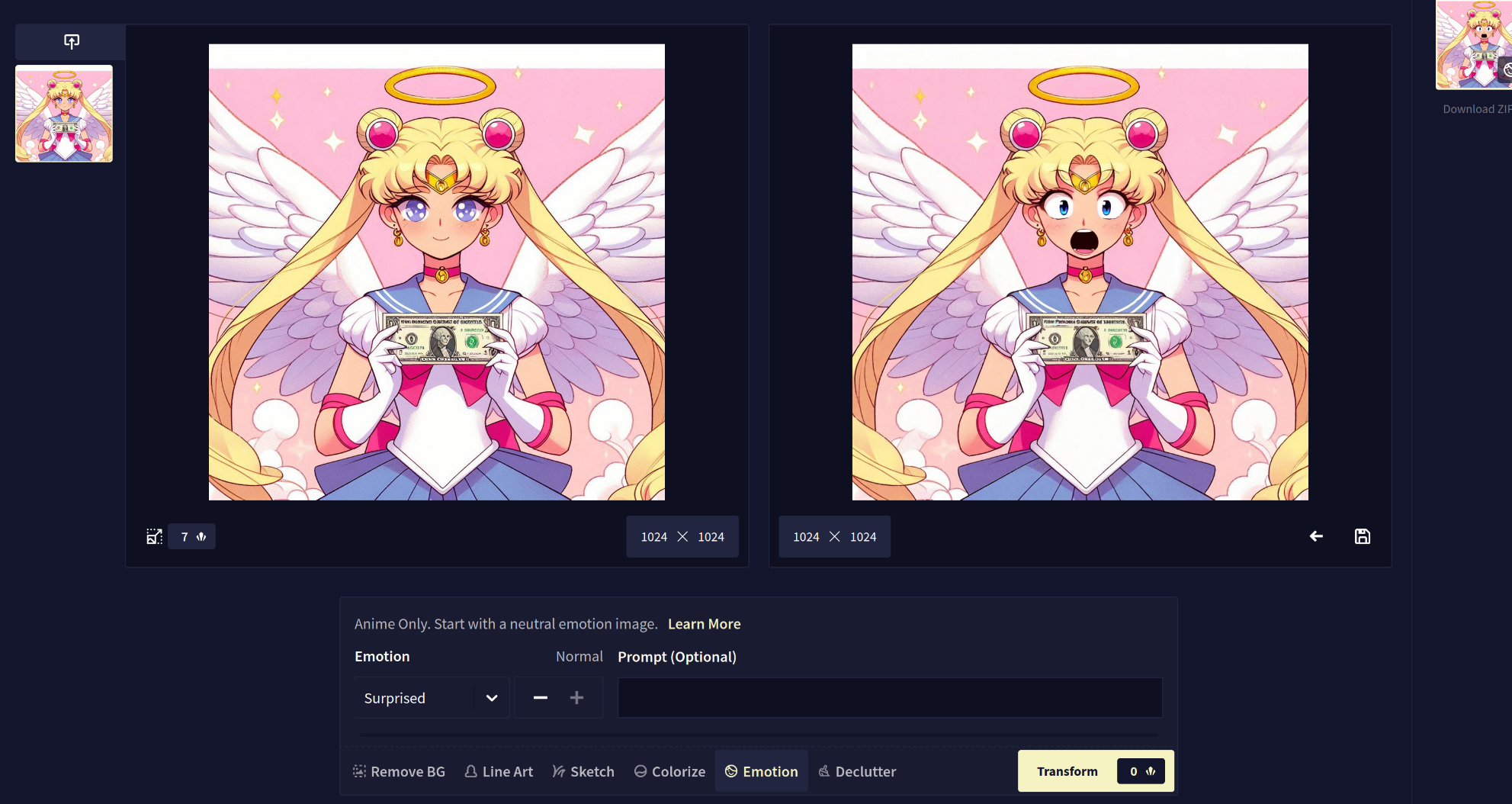
Line art (which removes the dollar bill, weirdly enough ) :

And of course inpainting:

There’s also some kind of outpainting, but like I said, I hardly ever use this tool. Here’s a tutorial if you want to read more about it:
https://blog.novelai.net/tutorial-intro-to-image-generation-ef644a1a4885
Oh and it’s completely privacy focused, so images are only saved to your computer.
cc: @M0oP0o@mander.xyz
I will give it a try as well always good to have more options, and I am not 100% only free options.
Funny note on the images. Mine where failures because I could not get a normal sailormoon with a floating bill with wings and a halo. Its funny to see all these with the anglemoon and normal money.
I have tried midjourney before. The results where… Underwhelming. Lots of odd artifacting, slow creation time and yes it had some issues with sailormoon.
I might try again, as it has been a while. It would be nice to have more control.
Oh I also tried local generation (forgot the name) and wooooow is my local PC bad at pictures (clearly can’t be my lack of ability it setting it up).
It probably isn’t worth the effort for most things, but one option might also be – and I’m not saying that this will work well, but a thought – using both. That is, if Bing Image Creator can generate images with content that you want but gets some details wrong and can’t do inpainting, but Midjourney can do inpainting, it might be possible to take a Bing-generated image that’s 90% of what you want and then inpaint the particular detail at issue using Midjourney. The inpainting will use the surrounding image as an input, so it should tend to try to generate similar image.
I’d guess that the problem is that an image generated with one model probably isn’t going to be terribly stable in another model – like, it probably won’t converge on exactly the same thing – but it might be that surrounding content is enough to hint it to do the right thing, if there’s enough of that context.
I mean, that’s basically – for a limited case – how AI upscaling works. It gets an image that the model didn’t generate, and then it tries to generate a new image, albeit with only slight “pressure” to modify rather than retain the existing image.
It might produce total garbage, too, but might be worth an experiment.
What I’d probably try to do if I were doing this locally is to feed my starting image into the thing to generate prompt terms that my local model can use to generate a similar-looking image, and include those when doing inpainting, since those prompt terms will be adapted to trying to create a reasonably-similar image using the different model. On Automatic1111, there’s an extension called Clip Interrogator that can do this (“image to text”).
Searching online, it looks like Midjourney has similar functionality, the
/describecommand.https://docs.midjourney.com/docs/describe
It’s not magic – I mean, end of the day, the model can only do what it’s been trained on – but I’ve found that to be helpful locally, since I’d bet that Bing and Midjourney expect different prompt terms for a given image.
Hmm. Well, that I’ve done. Like, was the problem that it was slow? I can believe it, but just as a sanity check, if you run on a CPU, pretty much everything is mind-bogglingly slow. Do you know if you were running it on a GPU, and if so, how much VRAM it has? And what you were using (like, Stable Diffusion 1.5, Stable Diffusion XL, Flux, etc?)
Ran it on my 6900 (nice) and although slow the main issue is it made things look like this:
It was stable diffusion XL.
kagis
If that’s 16GB, that should be more than fine for SDXL.
So, I haven’t done much with the base Stable Diffusion XL model. I could totally believe that it has very little Sailor Moon training data. But I am confident that there are models out there that do know about Sailor Moon. In fact, I’ll bet that there are LoRAs – like, little “add-on” models that add “knowledge” to a checkpoint model on Civitai specifically for generating Sailor Moon images.
Looks like I don’t have vanilla SDXL even installed at the moment to test.
downloads vanilla
Here’s what I get from vanilla SDXL for “Sailor Moon, anime”. Yeah, doesn’t look great, probably isn’t trained on Sailor Moon:
searches civitai
Yeah. There are. Doing a model search just for SDXL-based LoRA models:
https://civitai.com/search/models?baseModel=SDXL 1.0&modelType=LORA&sortBy=models_v9&query=sailor moon
goes to investigate
Trying out Animagine, which appears to be a checkpoint model aimed at anime derived from SDXL, with a Sailor Moon LoRA that targets that to add Sailor Moon training.
I guess you were going for an angelic Sailor Moon? Or angelic money, not sure there…doing an angelic Sailor Moon:
Doing a batch of 20 and grabbing my personal favorite:
I grabbed some of those prompt terms from the example images for the Sailor Moon LoRA on Civitai. Haven’t really tried experimenting with what works well. I dunno what’s up with those skirt colors, but it looks like the “multicolored skirt, white skirt” does it – maybe there are various uniforms that Sailor Moon wears in different series or something, since it looks like this LoRA knows about them and can use specific ones, as they have those different skirts and different prompt terms on the example images.
I just dropped the Animagine model in the models/Stable-diffusion directory in Automatic1111, and the Sailor Moon Tsukino Usagi LoRA in the models/Lora directory, chose the checkpoint model, included that
<lora:sailor_moon_animaginexl_v1:0.9>prompt term to make the render use that LoRA and some trigger terms.That’s 1024x1024. Then doing a 4x upscale to a 16GB 4096x4096 PNG using SwinIR_4x in img2img using the SD Ultimate Upscale script (which does a tiled upscale, so memory shouldn’t be an issue):
The above should be doable with an Automatic1111 install and your hardware and the above models.
EDIT: On Civitai, when you view example images, you can click the little “i” in a circle on the image to view what settings they used to create them.
EDIT2: It looks like the same guy that made a LoRA for Sailor Moon also did LoRAs for the other characters in her series, so if you want, like, training on Sailor Mars or whatever, looks like you could grab that and also add knowledge about her in.
Thanks for the more info. Yes my card was enough, I just suck and it was not fun. I am fine not having 4k level stuff, just want a few more tools.
Oh and I was going for normal sailormoon with angelic money