

2·
1 month agoIts highly dependent on implementation.
https://www.pugetsystems.com/labs/articles/stable-diffusion-performance-professional-gpus/
The experience on Linux is good (use docker otherwise python is dependency hell) but the basic torch based implementations (automatic, comfy) have bad performance. I have not managed to get shark to run on linux, the project is very windows focused and has no documentation for setup besides “run the installer”.
Basically all of the vram trickery in torch is dependent on xformers, which is low-level cuda code and therefore does not work on amd. And has a running project to port it, but it’s currently to incomplete to work.





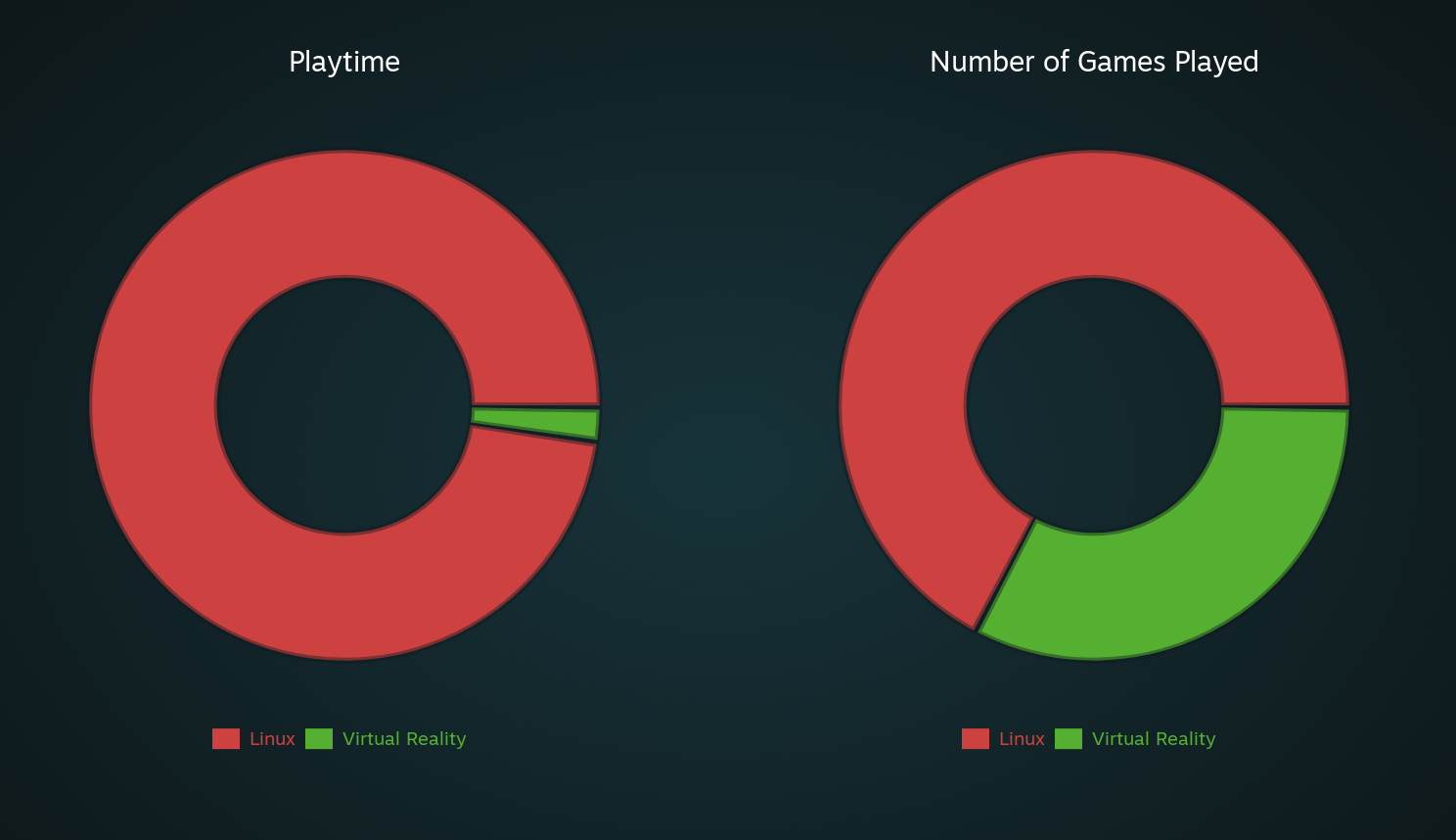
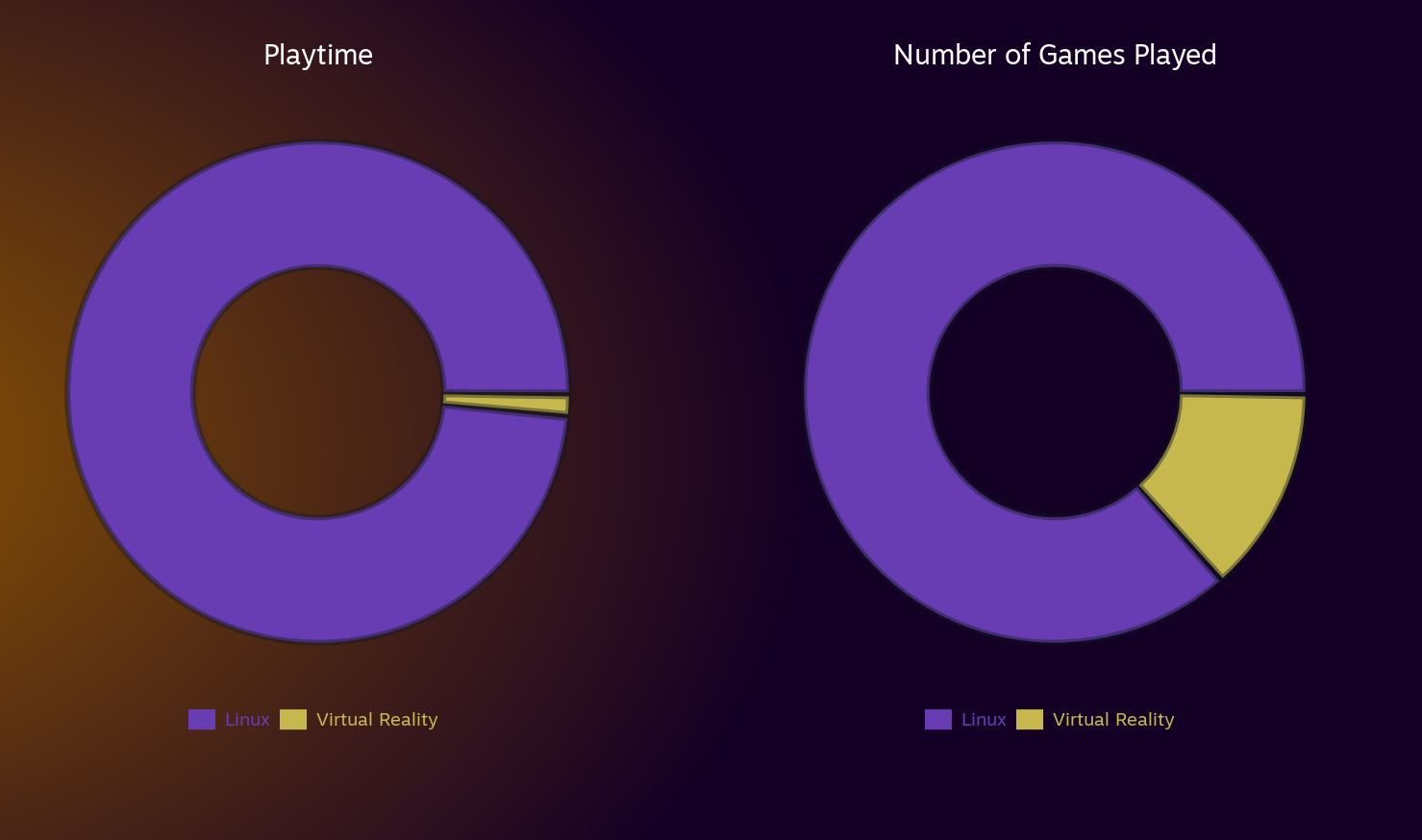

Similar principle but O(log(n)) istead of Stalin sorts O(n).