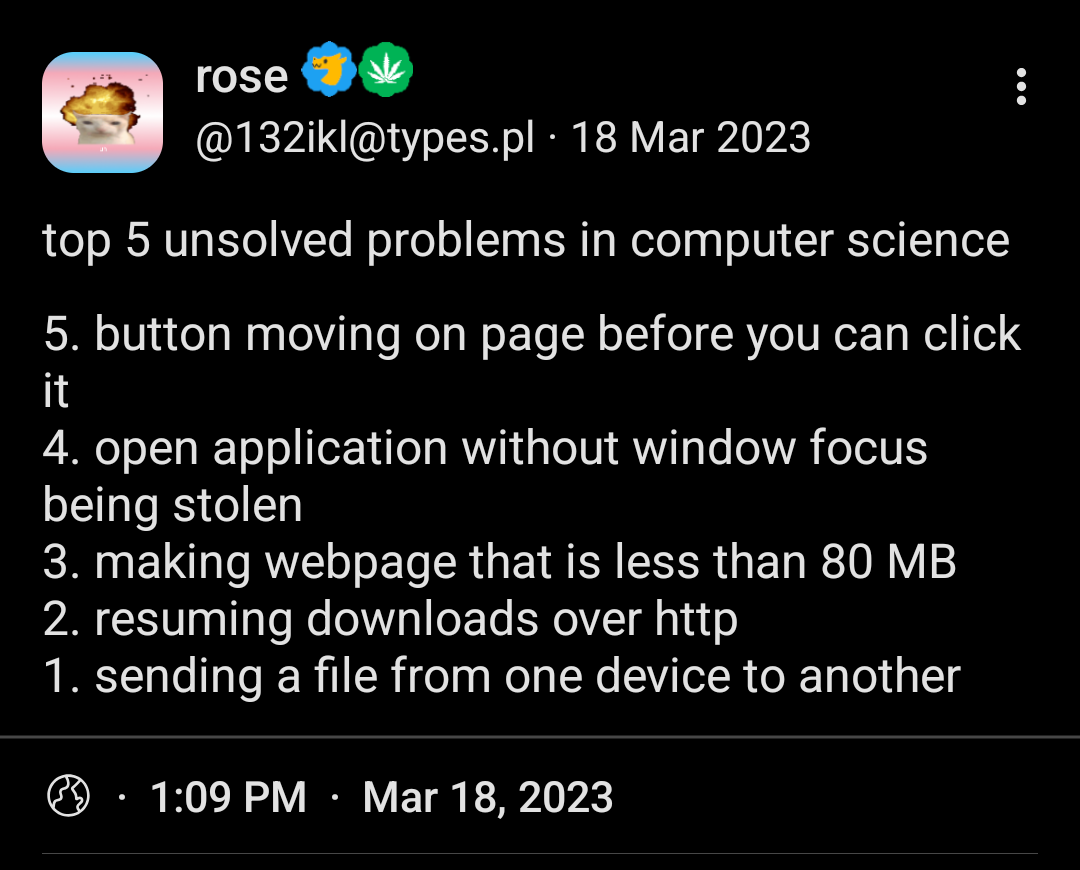
It should be able to resume where it left off. The HTTP Range header lets a client specify which part of a file they want. For a partially downloaded file, it can skip the part that has already been downloaded. If you’re downloading a 1000MB file and 700MB of it was already downloaded, you’d only need the last 300MB.
This is also how multithreaded downloaders work - each thread is requesting a different piece of the file.
I think wget may support resumable downloads but I’m not 100% sure.
I’ll try it out when I get time. I’m pretty sure Chrome can pause and resume downloads but I’m not sure if their state is preserved if you close and reopen the browser. Haven’t tested in Firefox.

{kind=link}
But what if your browser restarts? Wget? How do cookies complicate that?
It should be able to resume where it left off. The HTTP Range header lets a client specify which part of a file they want. For a partially downloaded file, it can skip the part that has already been downloaded. If you’re downloading a 1000MB file and 700MB of it was already downloaded, you’d only need the last 300MB.
This is also how multithreaded downloaders work - each thread is requesting a different piece of the file.
I think wget may support resumable downloads but I’m not 100% sure.
deleted by creator
I’ll try it out when I get time. I’m pretty sure Chrome can pause and resume downloads but I’m not sure if their state is preserved if you close and reopen the browser. Haven’t tested in Firefox.
Yes but do they actually do that?